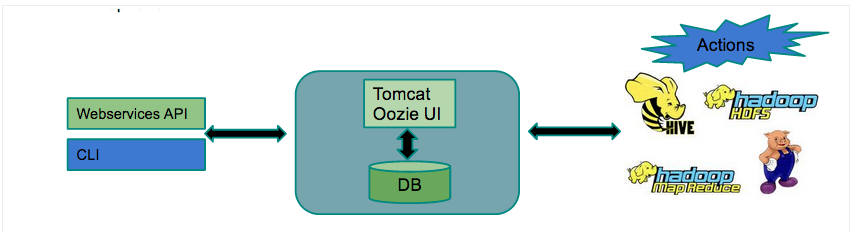
In this article, we would go through important aspects involved while setting up queues using YARN Capacity Scheduler.
Before, we setup the queue, let's first see how we could configure the amount of maximum memory to be utilized by YARN node managers. In order to configure a PHD cluster to utilize a specific amount of memory for YARN node managers, we could edit the parameter "yarn.nodemanager.resource.memory-mb" in yarn configuration file "/etc/gphd/hadoop/conf/yarn-site.xml". After a desired value has been defined, it needs a restart of YARN services for the change to take place.
yarn-site.xml
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>16384</value>
</property>
In the above example, we have assigned 16 GB of memory for utilization by YARN node managers per server.
We may now define multiple queues depending on the requirement for the operations which needs to be performed and give them a share of the cluster resources defined. However, in order to allow YARN to use capacity scheduler, we need to have parameter "yarn.resourcemanager.scheduler.class" defined in yarn-site.xml to use CapacityScheduler. In PHD, by default, the value is set to use CapacityScheduler, so we could straight away define the queues.
yarn-site.xml
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
Setting up the queues:
CapacityScheduler has a pre-defined queue called root. All queueus in the system are children of the root queue. In capacity-scheduler.xml, parameter "yarn.scheduler.capacity.root.queues" could be used to define child queues. For example, In order to create 3 queues, we could specify the name of the queues in a comma separated list.
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>alpha,beta,default</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
With the above change being done, now we could proceed further to specify the queue specific parameters. Parameters denoting queue specific properties follow a standard set of naming convention & they include the name of the queue for which they are relevant.
Here is an example of general syntax: yarn.scheduler.capacity.<queue-path>.<parameter>
where :
<queue-path> : identifies the name of the queue.
<parameter> : identifies the parameter whose value is being set.
Please refer to Apache Yarn Capacity Scheduler documentation for the complete list of configurable parameter.
Link:
http://hadoop.apache.org/docs/r2.0.5-alpha/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
Let's move on to set some major parameters
1)
Queue Resource Allocation related queue parameter:
a)
yarn.scheduler.capacity.<queue-path>.capacity
To set the percentage of cluster resource which must be allocated to these resources, we need to edit the value of the parameter yarn.scheduler.capacity.<queue-path>.capacity in capacity-scheduler.xml accordingly. In the below example, we set the queues to use 50%, 30% and 20% of the allocated cluster resources which was earlier set by "yarn.nodemanager.resource.memory-mb" per nodemanager.
Example below:
<property>
<name>yarn.scheduler.capacity.root.alpha.capacity</name>
<value>50</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.beta.capacity</name>
<value>30</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>20</value>
<description>Default queue target capacity.</description>
</property>
There are few other parameters as well which defines resource allocation and could be set, you could refer them on the Apache Yarn Capacity Scheduler documentation.
2) Queue Administration & Permissions related parameter:
a) yarn.scheduler.capacity.<queue-path>.state
To enable the queue to allow jobs / application to be submitted via them, the state of queue must be RUNNING, else you may receive error message stating that queue is STOPPED. RUNNING & STOPPED are the permissible values for this parameter.
Example below:
<property>
<name>yarn.scheduler.capacity.root.alpha.state</name>
<value>RUNNING</value>
<description>
The state of the default queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.beta.state</name>
<value>RUNNING</value>
<description>
The state of the default queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
<description>
The state of the default queue. State can be one of RUNNING or STOPPED.
</description>
</property>
b) yarn.scheduler.capacity.root.<queue-path>.acl_submit_applications
To enable a particular user to submit a job / application to a specific queue, we must define the username / group in a comma separated list. A special value of * allows all the users to submit jobs / application to the queue.
Example format for specifying the list of users:
1) <value>user1,user2</value> : This indicates that user1 and user2 are allowed.
2) <value>user1,user2 group1,group2</value> : This indicates that user1, user2 and all the users from group1 & group2 are allowed.
3) <value>group1,group2</value>: This indicates that all the users from group1 & group2 are allowed.
Under this parameter, first thing you must define is the value for the parameter as "hadoop,yarn,mapped,hdfs" for non-leaf root queue, it ensures that only the special users could use all the queues. Since the child queues inherit permissions of their root queue, and by default its "*", thus if you don't restrict the list at root queue, all the user may still be able to run jobs on any of the queues. By specifying "hadoop,yarn,mapped,hdfs" for non-leaf root queue, you could control user access based on specific child queues.
Non-Leaf Root queue :
Example below:
<property>
<name>yarn.scheduler.capacity.root.acl_submit_applications</name>
<value>hadoop,yarn,mapred,hdfs</value>
<description>
The ACL of who can submit jobs to the root queue.
</description>
</property>
Child Queue under root queue / Leaf child queue:
Example below:
<property>
<name>yarn.scheduler.capacity.root.alpha.acl_submit_applications</name>
<value>sap_user hadoopusers</value>
<description>
The ACL of who can submit jobs to the alpha queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.beta.acl_submit_applications</name>
<value>bi_user,etl_user failgroup</value>
<description>
The ACL of who can submit jobs to the beta queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>adhoc_user hadoopusers</value>
<description>
The ACL of who can submit jobs to the default queue.
</description>
</property>
c) yarn.scheduler.capacity.<queue-path>.acl_administer_queue
To set the list of administrator who could manage an application on a queue, you may set the username in a comma separated list for this parameter. A special value of * allows all the users to administrator an application running on a queue.
You may define the below properties as we defined for acl_submit_applications. Same syntax is followed.
Example below:
<property>
<name>yarn.scheduler.capacity.root.alpha.acl_administer_queue</name>
<value>sap_user</value>
<description>
The ACL of who can administer jobs on the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.beta.acl_administer_queue</name>
<value>bi_user,etl_user</value>
<description>
The ACL of who can administer jobs on the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>adhoc_user</value>
<description>
The ACL of who can administer jobs on the default queue.
</description>
</property>
3) There are "Running and Pending Application Limits" related other queue parameters, which could also be defined but we have not covered in this article.
Bringing the queues in effect:
Once you have defined the required parameters in capacity-scheduler.xml file, now run the below command to bring the changes in effect.
yarn rmadmin -refreshQueues
After successful completion of the above command, you may verify if the queues are setup using below 2 options:
1) hadoop queue -list
[root@phd11-nn ~]# hadoop queue -list
DEPRECATED: Use of this script to execute mapred command is deprecated.
Instead use the mapred command for it.
14/01/16 22:10:25 INFO service.AbstractService: Service:org.apache.hadoop.yarn.client.YarnClientImpl is inited.
14/01/16 22:10:25 INFO service.AbstractService: Service:org.apache.hadoop.yarn.client.YarnClientImpl is started.
======================
Queue Name : alpha
Queue State : running
Scheduling Info : Capacity: 50.0, MaximumCapacity: 1.0, CurrentCapacity: 0.0
======================
Queue Name : beta
Queue State : running
Scheduling Info : Capacity: 30.0, MaximumCapacity: 1.0, CurrentCapacity: 0.0
======================
Queue Name : default
Queue State : running
Scheduling Info : Capacity: 20.0, MaximumCapacity: 1.0, CurrentCapacity: 0.0
2) By opening YARN resourcemanager GUI, and navigating to the scheduler tab. Link for resroucemanager GUI is : http://<Resouremanager-hostname>:8088.
where 8088 is the default port & replace <Resouremanager-hostname> with the hostname as per your PHD cluster. Below is an example for the same depicting one of the queue created "alpha"
Get ready to execute a job by submitting it to a specific queue:
Before, you execute any hadoop job, use the below command to identify the queue names on which you could submit your jobs.
[fail_user@phd11-nn ~]$ id
uid=507(fail_user) gid=507(failgroup) groups=507(failgroup)
[fail_user@phd11-nn ~]$ hadoop queue -showacls
Queue acls for user : fail_user
Queue Operations
=====================
root ADMINISTER_QUEUE
alpha ADMINISTER_QUEUE
beta ADMINISTER_QUEUE,SUBMIT_APPLICATIONS
default ADMINISTER_QUEUE
If you see the above output, fail_user could submit application only on beta queue, since its part of "failgroup" and have been assigned only to beta queue in capacity-scheduler.xml as described earlier.
Let's move on a bit closer to running our first job in this article. In order to submit an application, you have to use the parameter -Dmapred.job.queue.name=<queue-name> or -Dmapred.job.queuename=<queue-name>
The below examples illustrates how to run a job on a specific queue.
[fail_user@phd11-nn ~]$ yarn jar /usr/lib/gphd/hadoop-mapreduce/hadoop-mapreduce-examples-2.0.5-alpha-gphd-2.1.1.0.jar wordcount -D mapreduce.job.queuename=beta /tmp/test_input /user/fail_user/test_output
14/01/17 23:15:31 INFO service.AbstractService: Service:org.apache.hadoop.yarn.client.YarnClientImpl is inited.
14/01/17 23:15:31 INFO service.AbstractService: Service:org.apache.hadoop.yarn.client.YarnClientImpl is started.
14/01/17 23:15:31 INFO input.FileInputFormat: Total input paths to process : 1
14/01/17 23:15:31 INFO mapreduce.JobSubmitter: number of splits:1
In DefaultPathResolver.java. Path = hdfs://phda2/user/fail_user/test_output
14/01/17 23:15:32 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1390019915506_0001
14/01/17 23:15:33 INFO client.YarnClientImpl: Submitted application application_1390019915506_0001 to ResourceManager at phd11-nn.saturn.local/10.110.127.195:8032
14/01/17 23:15:33 INFO mapreduce.Job: The url to track the job: http://phd11-nn.saturn.local:8088/proxy/application_1390019915506_0001/
14/01/17 23:15:33 INFO mapreduce.Job: Running job: job_1390019915506_0001
2014-01-17T23:15:40.702-0800: 11.670: [GC2014-01-17T23:15:40.702-0800: 11.670: [ParNew: 272640K->18064K(306688K), 0.0653230 secs] 272640K->18064K(989952K), 0.0654490 secs] [Times: user=0.06 sys=0.04, real=0.06 secs]
14/01/17 23:15:41 INFO mapreduce.Job: Job job_1390019915506_0001 running in uber mode : false
14/01/17 23:15:41 INFO mapreduce.Job: map 0% reduce 0%
14/01/17 23:15:51 INFO mapreduce.Job: map 100% reduce 0%
14/01/17 23:15:58 INFO mapreduce.Job: map 100% reduce 100%
14/01/17 23:15:58 INFO mapreduce.Job: Job job_1390019915506_0001 completed successfully
While the job is executing, you may also monitor resource manger GUI to see on what queue is the job submitted. Here is a snapshot of the name. In the snapshot below, green color indicates the queue which is being used by the above word count application.

Now, let's see what happens when another queue is used on which fail_user is not allowed to submit applications. This must fail.
[fail_user@phd11-nn ~]$ yarn jar /usr/lib/gphd/hadoop-mapreduce/hadoop-mapreduce-examples-2.0.5-alpha-gphd-2.1.1.0.jar wordcount -D mapreduce.job.queuename=alpha /tmp/test_input /user/fail_user/test_output_alpha
14/01/17 23:20:07 INFO service.AbstractService: Service:org.apache.hadoop.yarn.client.YarnClientImpl is inited.
14/01/17 23:20:07 INFO service.AbstractService: Service:org.apache.hadoop.yarn.client.YarnClientImpl is started.
14/01/17 23:20:07 INFO input.FileInputFormat: Total input paths to process : 1
14/01/17 23:20:07 INFO mapreduce.JobSubmitter: number of splits:1
In DefaultPathResolver.java. Path = hdfs://phda2/user/fail_user/test_output_alpha
14/01/17 23:20:08 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1390019915506_0002
14/01/17 23:20:08 INFO client.YarnClientImpl: Submitted application application_1390019915506_0002 to ResourceManager at phd11-nn.saturn.local/10.110.127.195:8032
14/01/17 23:20:08 INFO mapreduce.JobSubmitter: Cleaning up the staging area /user/fail_user/.staging/job_1390019915506_0002
14/01/17 23:20:08 ERROR security.UserGroupInformation: PriviledgedActionException as:fail_user (auth:SIMPLE) cause:java.io.IOException: Failed to run job : org.apache.hadoop.security.AccessControlException: User fail_user cannot submit applications to queue root.alpha
java.io.IOException: Failed to run job : org.apache.hadoop.security.AccessControlException: User fail_user cannot submit applications to queue root.alpha
at org.apache.hadoop.mapred.YARNRunner.submitJob(YARNRunner.java:307)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:395)
at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1218)
at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1215)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1478)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1215)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1236)
at org.apache.hadoop.examples.WordCount.main(WordCount.java:84)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:72)
at org.apache.hadoop.util.ProgramDriver.driver(ProgramDriver.java:144)
at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:68)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.main(RunJar.java:212)